


We want machines to find patterns that are too complex for us to identify using simple trendlines and data visualization, but the reasoning behind the prediction made by a machine learning (ML) model or the behavior of artificial intelligence (AI) can often be extremely difficult to interpret. The challenge with this is that we humans want to question and understand the WHY behind the advice we’re given. Understanding WHY can increase our confidence in the advice we receive and broaden our thinking when the explanation helps us see factors that our own decision-making process neglected. Unfortunately, many ML/AI techniques are so complex they are effectively black boxes that merely spit out an answer with no explanation of what drove that answer. Without the ability to understand what factors are influencing the decision, many ML/AI solutions struggle to gain adoption. Most famously, IBM Watson Health initially failed to receive approval from oncologists because it couldn’t explain what factors were leading it determine a patient had cancer.
Man vs. Machine
One of the challenges with interpretability of ML/AI is that we usually think about human decision-making in terms of heuristic rules like “if it’s a windy November day in St. Louis and there are thick clouds in the sky, I expect that it will be cold,” but ML/AI works differently in a couple of key ways. First, most ML/AI models include hundreds or even thousands of variables used in the decision making: precipitation, cloud type, cloud density, cloud altitude, wind speed, wind direction, relative humidity, time since last snow, and the list goes on. In addition, the ML/AI will look at not just these variables in isolation, but how they interact with each other as well, making the number of possible “rules” exponentially bigger.
Second, ML/AI models predict probabilities rather than judgements. That is, the output of our weather prediction model described above wouldn’t just simply say “yes, I think it will be cold.” Instead, the model would produce a whole set of possible outcomes and their probabilities: 20% below freezing, 70% just above freezing, 10% warm. Looking to understand “why did you predict that the chance of being below freezing was 1 in 5?” is a more complicated question to answer than “why do you think it’ll be cold?” As you might be starting to see, ML/AI models are hard to interpret.
Pig+Static=Airliner?
In contrast to the apparent ML/AI black box conundrum, there are data scientists and computer scientists who understand the innerworkings of ML/AI decision-making so well, that they can intentionally trick the ML/AI to respond with a very specific and different outcome than expected. For instance, both the left and right images below are easily recognizable by a human as images of a “pig.” In fact, almost all humans would say those are the same picture of a pig. However, the image on the right has been altered using a very precise and intentional form of imperceptible “static.” This static, not noticeable by humans, will trick particular image recognition algorithms to incorrectly identify the picture on the right as an “airliner” instead of a pig. There’s nothing special about pigs and airliners here, either. Someone with the right skills and right information can make this work with nearly any pairing. What this tells us is that using even more technology on top of our ML/AI models, we should be able to provide a human-understandable interpretation of the underlying ML/AI model.
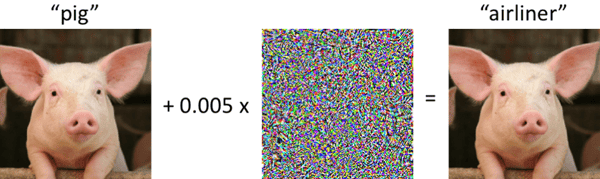
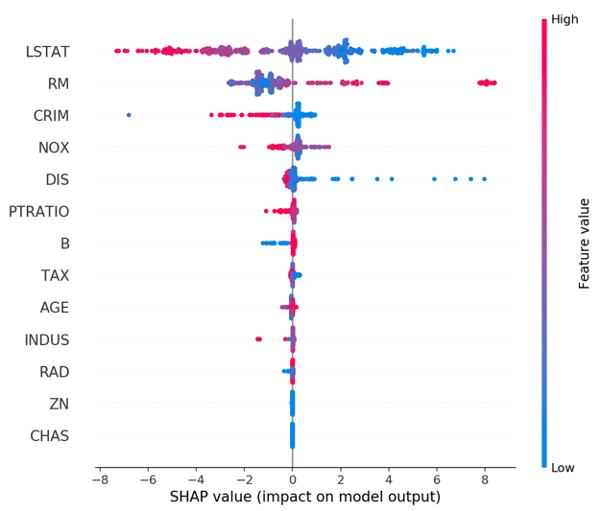
SHAP Shows the Way
As a result of this focus on the need for an ML/AI to explain itself, there’s been a lot of recent work on creating tools to help present models and results in an interpretable way. One of the most popular methods for this today is called “SHAP.” What SHAP analysis provides is the answer to “what factors made this outcome in this particular situation more or less likely to occur?” In fact, the work on SHAP has even produced some powerful and creative data visualizations. The global view of SHAP feature importance for an ML/AI predictive model shown in the diagram below is one way of trying to understand at a glance, which individual variables have a big impact and what values of that variable encourage what kind of outcome.
Another powerful visualization of SHAP values is something called a “force diagram.” A force diagram shows us which attributes are increasing the likelihood of a higher outcome (those in red) and which attributes are counteracting that (those in blue). In the example below, the LSAT of 4.98 is strongly pushing the outcome higher, whereas RM and NOX are making small impacts pushing the outcome lower. Don’t assume however, that LSAT of 4.98 always has the same influence on the outcome. In another case, the interaction between LSAT and NOX (for example) could create an entirely different outcome. SHAP does, however, answer the question “why do you think the outcome is going to be higher in this case?”

While most of the trends in ML/AI have been in making algorithms ever more sophisticated, the NEED for interpretable models is clear, and techniques like SHAP are a step in the right direction.
Read more:
- https://github.com/slundberg/shap
- https://christophm.github.io/interpretable-ml-book/
- https://www.forbes.com/sites/jasonbloomberg/2018/09/16/dont-trust-artificial-intelligence-time-to-open-the-ai-black-box/#5650ed6e3b4a
- https://spectrum.ieee.org/cars-that-think/transportation/sensors/slight-street-sign-modifications-can-fool-machine-learning-algorithms
- https://www.vox.com/future-perfect/2019/4/8/18297410/ai-tesla-self-driving-cars-adversarial-machine-learning
- https://towardsdatascience.com/shap-a-reliable-way-to-analyze-your-model-interpretability-874294d30af6
Have any questions or want to know more? We have answers.



